



The importance of crypto license in Europe
Crypto license in Europe an official document giving you permission to conduct a crypto-asset-sharing business. It also increases the trust of users who prefer to use only official services that have proven themselves to be reliable. Europe is one of the most promising for the conduct of such an enterprise and for the development of financial technologies. In Europe, they are very developed, there are many firms dealing in one way or another with alternative currencies. The new companies were given easier registration.

How to get a license for crypto license in Europe
There are two types of such documents. The first is the license of the exchange operator. It can be obtained if you are engaged in the exchange of crypto assets for fiat funds (dollars, euros, other currency). Once you have been granted official status, you will have the right to provide such exchange services. Earnings at the same time will go at the expense of the commission. What percentage to put – you decide. Usually crypto exchangers set a very small percentage, like 0.01%. Before doing so, calculate your company start-up costs and estimated income. The second type of such document is the license of the cryptocurrency wallet depository. It gives the right to create encryption keys for its clients, which help them to keep their funds in safety, calculated in bitcoins, ethers and other similar alternative currencies. You can obtain both licenses if you intend to carry out both activities. By the way, businessmen who are not residents of this country can get a crypto license in Europe.
How does this process work:
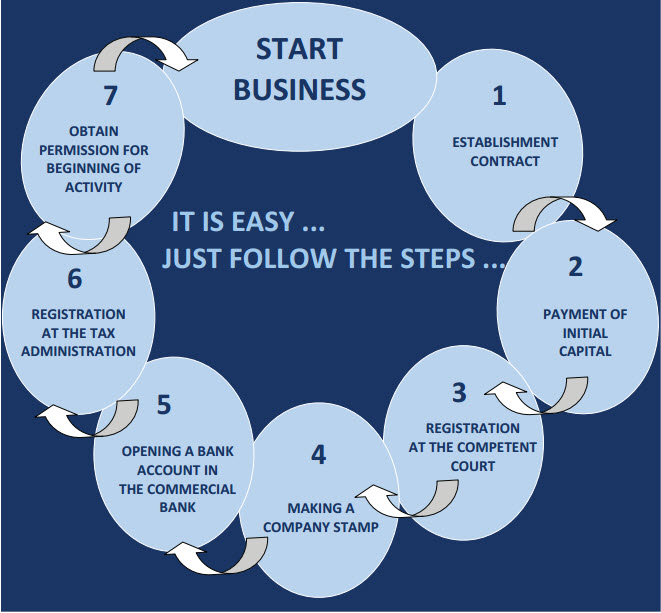
First stage – establishment of a limited liability company with at least one local staff and authorized capital of 2,500 or more euros work on compliance with the basic requirements: identification of clients, the presence of a website, interaction with the tax police implementation of customer verification mechanisms permission application. There are a number of complex requirements to the “know your client” (KYC) policy. It is aimed at making sure of the legal sources of the funds and in general to obtain full information on everything related to income and exchange (but not necessarily about the client, although they can also present such requirements). Verification and identification is needed in such cases as the beginning of the client-company cooperation (in other words, registration of a new client on the site) or the exchange of funds. In the second case, you can check at all each time or if you exceed a certain limit (for example, if you exchange more than 1000 dollars).

Why a crypto businessman makes sense to choose Europe
For those who deal with cryptocurrencies, obtaining a crypto license in Europe will be a more convenient option. The EU states will gradually legalize anything related to alternative currencies and conditions most suitable for doing such business. For those engaged in financial activities in Europe is very loyal legislation. In addition, there are no restrictions for non-residents – so you can open a company to exchange or store cryptocurrency. Employment of local specialists is desirable, but not mandatory. You can do business alone – but all the information about yourself must be provided. You should document all information about directors, shareholders, confirm that none of them have a criminal record, as well as draw up a charter and memorandum of your company.